Quality Gates for AI Content: Stop Hallucinations Before They Publish

Eight episodes in, and our pipeline can ingest RSS feeds, score content, generate articles with Gemini, apply persona templates, capture screenshots, and push to Git. It's a beautiful machine. But if you've spent any time shipping AI-generated content to production, you already know the nightmare lurking around every corner: hallucinated facts, duplicated posts, and dead source links that make your readers distrust everything you publish.
Today we add the safety net: automated quality gates. These run before anything touches the filesystem, and they'll save you from the kind of embarrassing corrections that erode reader trust in minutes.
Why Quality Gates Can't Be Optional
LLMs are extraordinarily good at sounding confident while being wrong. They'll cite URLs that don't exist, restate last week's post with a new title, and occasionally produce content that directly contradicts the source material. When this goes undetected in an automated pipeline, it publishes — and your readers notice before you do.
The three failure modes we're guarding against:
1. Hallucinated sources — URLs or claims that don't exist or don't say what the LLM claims
2. Near-duplicate content — slightly reworded versions of posts already in your archive
3. Low-quality generation — posts that are too short, have broken JSON structure, or fail basic heuristics
Here's how our quality gate workflow fits into the pipeline:
Step 1: Source URL Verification with HTTP Nodes
When Gemini generates a post, it may include URLs in the sources array or inline in the markdown. Before the post is saved, we verify that each URL is reachable and returns a 2xx status.
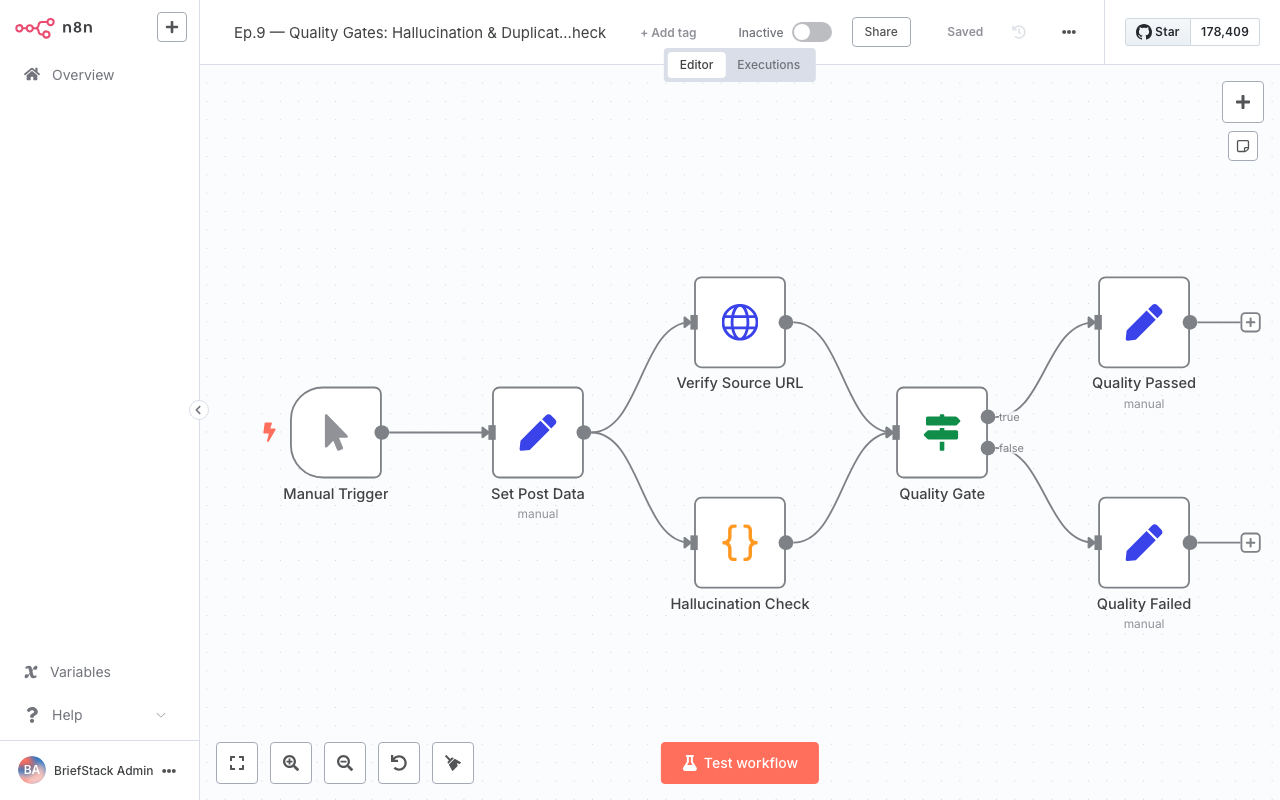
The workflow editor showing the quality gate nodes chained together — source verification feeds into duplicate detection, then into heuristic checks, with a reject branch going to Slack notifications.
In n8n, add an HTTP Request node configured like this:
{
"method": "HEAD",
"url": "={{ $json.source_url }}",
"options": {
"redirect": { "redirect": { "followRedirects": true, "maxRedirects": 5 } },
"timeout": 8000
},
"onError": "continueRegularOutput"
}Using HEAD instead of GET is faster — we only care about the status code, not the body. Set onError to continueRegularOutput so the workflow doesn't halt on a 404; instead, we'll handle the failure downstream.
After the HTTP Request, add a Code node that accumulates the verification results:
const post = $('Set: Post Data').first().json;
const sources = post.sources || [];
const results = items.map(item => ({
url: item.json.url,
status: item.json.statusCode,
ok: item.json.statusCode >= 200 && item.json.statusCode < 400
}));
const failedSources = results.filter(r => !r.ok);
const verificationPassed = failedSources.length === 0;
return [{
json: {
...post,
_qa: {
sourceVerification: { passed: verificationPassed, failed: failedSources }
}
}
}];If any source returns 4xx or 5xx, verificationPassed is false and the downstream IF node routes to the rejection branch.
Step 2: Cosine Similarity for Duplicate Detection
Checking if a new post is too similar to an existing one requires text similarity. We use term-frequency cosine similarity — fast enough for a content pipeline and accurate enough to catch near-duplicates.
Add a Code node that reads your existing post slugs and compares titles and body extracts:
const fs = require('fs');
const path = require('path');
function tokenize(text) {
return text.toLowerCase()
.replace(/[^a-z0-9\s]/g, '')
.split(/\s+/)
.filter(w => w.length > 3);
}
function tfVector(tokens) {
const vec = {};
for (const t of tokens) vec[t] = (vec[t] || 0) + 1;
return vec;
}
function cosineSim(a, b) {
const keys = new Set([...Object.keys(a), ...Object.keys(b)]);
let dot = 0, normA = 0, normB = 0;
for (const k of keys) {
const va = a[k] || 0, vb = b[k] || 0;
dot += va * vb;
normA += va * va;
normB += vb * vb;
}
return normA && normB ? dot / (Math.sqrt(normA) * Math.sqrt(normB)) : 0;
}
const CONTENT_DIR = '/home/node/briefstack/frontend/src/content/blog';
const newPost = items[0].json;
const newText = (newPost.title + ' ' + newPost.body_markdown.slice(0, 2000));
const newVec = tfVector(tokenize(newText));
const files = fs.readdirSync(CONTENT_DIR).filter(f => f.endsWith('.json'));
let maxSim = 0;
let mostSimilarSlug = null;
for (const file of files) {
const existing = JSON.parse(fs.readFileSync(path.join(CONTENT_DIR, file), 'utf8'));
if (existing.slug === newPost.slug) continue; // skip self
const existText = (existing.title + ' ' + (existing.body_markdown || '').slice(0, 2000));
const sim = cosineSim(newVec, tfVector(tokenize(existText)));
if (sim > maxSim) { maxSim = sim; mostSimilarSlug = existing.slug; }
}
const DUPLICATE_THRESHOLD = 0.82; // tune this per your content style
const isDuplicate = maxSim > DUPLICATE_THRESHOLD;
return [{ json: {
...newPost,
_qa: {
...newPost._qa,
duplicateCheck: { passed: !isDuplicate, similarity: maxSim, mostSimilarSlug }
}
}}];The threshold of 0.82 works well for English tech content. Lower it to 0.75 for shorter posts; raise to 0.88 if you're intentionally writing follow-up episodes in the same series.
Step 3: Hallucination Heuristics in Prompts
You can't catch all hallucinations post-hoc — some require domain expertise. But you can bake heuristics into both your prompts and your validation code.
Prompt-level heuristics (instruct the model up front):
IMPORTANT RULES:
- Only include sources you are certain exist. If unsure, omit the source.
- Do not invent version numbers, release dates, or benchmark figures.
- If you reference a GitHub repo, it must match the format: https://github.com/<owner>/<repo>
- Never state statistics without a verifiable source URL in the sources array.Code-level heuristics in your quality gate node:
const post = items[0].json;
const body = post.body_markdown || '';
const issues = [];
// Too short — likely truncated or failed generation
if (post.word_count < 600) issues.push('word_count_too_low');
// Meta description out of spec
if (!post.meta_description || post.meta_description.length < 100) {
issues.push('meta_description_missing_or_short');
}
// Contains placeholder text the model forgot to fill in
if (body.match(/\[INSERT|TODO|PLACEHOLDER|FIXME/i)) {
issues.push('contains_placeholder_text');
}
// GitHub URLs with invalid format (hallucinated repos)
const ghUrls = body.match(/https:\/\/github\.com\/[\w-]+\/[\w.-]+/g) || [];
for (const url of ghUrls) {
if (url.split('/').length !== 5) issues.push(invalid_github_url: ${url});
}
// Suspiciously round numbers often indicate hallucination
if (body.match(/\b(100%|10x|1000x)\b/g)?.length > 3) {
issues.push('suspiciously_many_round_numbers');
}
const heuristicsPassed = issues.length === 0;
return [{ json: {
...post,
_qa: {
...post._qa,
heuristics: { passed: heuristicsPassed, issues }
}
}}];Step 4: Routing and Alerts on Quality Failures
The n8n dashboard shows workflow execution history — a quick glance tells you how many runs succeeded vs. failed quality gates today.
After all three checks run, add an IF node that reads _qa:
// IF node condition (using expression)
{{ $json._qa.sourceVerification.passed && $json._qa.duplicateCheck.passed && $json._qa.heuristics.passed }}True branch → strip the _qa field and pass to the publish step (Episode 8's Git workflow).
False branch → send a Slack or email alert:
// Code node: build Slack message
const qa = items[0].json._qa;
const lines = [
Quality gate FAILED for \${items[0].json.slug}\`,
qa.sourceVerification.failed.length
? • Dead sources: ${qa.sourceVerification.failed.map(f => f.url).join(', ')}
: null,
!qa.duplicateCheck.passed
? • Duplicate of \${qa.duplicateCheck.mostSimilarSlug}\ (similarity: ${(qa.duplicateCheck.similarity * 100).toFixed(1)}%)
: null,
qa.heuristics.issues.length
? • Heuristic issues: ${qa.heuristics.issues.join(', ')}
: null,
].filter(Boolean).join('\n');
return [{ json: { text: lines } }];Wire this to an HTTP Request node pointing to your Slack webhook URL. The webhook should be stored as an n8n credential, not hardcoded.
Tuning the Gates Over Time
Quality gates are not set-and-forget. The first two weeks will feel like the gate is blocking too much — lower thresholds, fix prompts, and observe. By week four, you'll have found the sweet spot where the gate catches real problems without creating false positives that waste your time reviewing.
Key metrics to track in your workflow execution logs:
| Metric | Target |
|---|---|
| Source verification pass rate | > 95% |
| Duplicate detection false positives | < 5% |
| Heuristic failures per 100 runs | < 8 |
| Mean time to alert on failure | < 2 min |
Store rejected posts in a separate _rejected/
directory with the _qa data attached. After 30 days, review the patterns — they'll tell you exactly which prompt improvements to make next.
FAQ
Does cosine similarity work for non-English content?
Yes, with caveats. The tokenization regex needs to be updated to handle unicode characters correctly. For CJK languages, use character n-grams instead of word tokens. The threshold may need recalibration since CJK text tokenizes differently from English.
What's the performance cost of running these checks on every post?
Source verification adds 1–5 seconds per URL (network I/O). Cosine similarity over 500 existing posts takes under 200ms in the Code node. Total overhead per post is typically 3–15 seconds — completely acceptable for a content pipeline that runs every few hours.
Can I use embeddings instead of cosine similarity for duplicate detection?
Yes, and embeddings (e.g., from the Gemini Embedding API) will give you better semantic similarity than TF-IDF cosine. The tradeoff is an additional API call per post. For pipelines with > 1000 existing posts, embeddings are worth the cost. For smaller archives, TF-IDF is fast and free.
How do I handle false positives in the duplicate check for intentional follow-up posts?
Add a series field allowlist. If post.series` is non-null, skip the duplicate check or raise the threshold to 0.92. Series episodes intentionally share vocabulary and topic clusters, so a lower threshold creates too many false positives.
In the final episode, we'll wire all sub-workflows together into one end-to-end pipeline, add an error workflow with retry strategy, and talk through production hardening and monitoring. You're one episode away from a fully automated, quality-gated content machine.